




Digital twinning – building a virtual replica of a physical machine or process – has been long discussed through the “Industry 4.0” and “smart manufacturing” optics: a futuristic, investment-heavy digital wonder to admire. However, as the technology is maturing, its actual adoption is growing in different ways than imagined a couple of years ago.
As of today, digital twins provide manufacturers of different sizes with real-time data but also understanding of processes that allows informed decision-making. Let’s look at how this technology is actually used in manufacturing, how to know if your organization is ready, and how to elicit ROI with more confidence.
What is a digital twin in manufacturing?
A digital twin is a virtual representation of a physical asset, process, or production system that is continuously updated using real-world data. Unlike, say, a dashboard, a digital twin can reflect not just the current conditions but also behavior and constraints. This means it allows manufacturers to understand not just what happens but why it happens – and also simulate operations under hypothetical scenarios.
This latter point is important – not every visualization or IoT dashboard is, strictly speaking, a digital twin. Real digital twinning is not just about monitoring, but also modeling: context, structure, some level of behavioral logic. It is essentially the virtual version of the real machine or line that you’re not anxious to break.
Generally, this kind of system combines three layers:
- Data collection – that is, the sensors, PLCs, and IoT devices that generate data (machine status, throughput, temperature – whatever is relevant to modeling)
- Data integration and processing – this is where the information is aggregated, cleaned, and aligned
- Modeling & simulation – the actual digital “clone”, ranging from rule-based logic to advanced simulation or ML models. More advanced setups use techniques from frameworks like PyTorch for predictive modeling. Platforms like NVIDIA Omniverse can also support physics of the simulated environments. There’s a separate substack for spatial applications, including tools like ArcGIS.
All this is meant as an upgrade upon monitoring – since this simulated reality is meant to help understand what happens under this or that condition.
Why companies start thinking about the digital twin technology
There has been a lot of “buzz” about digital twinning, but this alone wouldn’t have been enough to make manufacturing companies actually adopt the technology (which they absolutely do). In most cases, the interest starts with recognizing operational friction when scaling:
- data is generated but disconnected
- production, maintenance and planning teams each have their own “reality”
- root cause analysis of issues relies on incomplete information, etc.
This is where reporting and dashboards gradually stop being enough because they show “snapshots” of what has already happened.
By this time, companies will typically have also considered predictive maintenance, Internet of Things deployments (where surprisingly large amounts of data become available at once), or have started attempts at improving planning accuracy. From these angles, digital twinning is the logical next step: “we have the data, how do we use it best?”
Practical applications of digital twins and use cases
There are several main practical applications of digital twins in the manufacturing industry – and in most real-world implementations, companies start by focusing on some particular operational pain point before expanding to broader modeling.
Predictive maintenance and equipment monitoring
Arguably the most common and mature application is monitoring machine health and predicting potential issues before they happen. The models are used to track equipment condition in real-time, compare actual behavior against expected performance and detect anomalies. This is a common first step into the digital twinning domain, since it delivers a clear, localized outcome: reducing downtime – and full system modeling is often not even necessary.
Production monitoring and operational visibility
Digital twin components can help consolidate data from machines, MES, ERP, and highlight delays or deviations in real time. The difference between this and a dashboard is understanding the interaction between the different parts of the production system.
Process optimization and bottleneck analysis
This is where things get more advanced and interesting: digital twins enable manufacturers to analyze what happens to the production flow if one part of the system is changed. This is useful in several situations:
- identifying hidden bottlenecks in multi-step processes
- testing adjustments in cycle times or resource allocation
- evaluating the impact of layout or scheduling changes
Scenario simulation
You can also use digital twins to simulate operational scenarios before risking with actual physical equipment. This provides answers to questions like “What if we increase output on Line A by 15%?” or “What if we shift production between two facilities?” Of course, this requires high data quality and superior system integration, so this is considered a rather mature level of implementation.
Advanced applications
In more complex environments, some manufacturers are starting to explore digital twins for:
- Cross-facility production coordination
- Synchronizing supply chain with production output
- Optimizing entire production ecosystems with AI
These use cases are promising but still largely considered experimental. However, the rest have already demonstrated benefits and are being adopted very actively.
Real-world benefits and ROI
While it’s tempting to set benchmarks like “implement a digital twin and see 22% improvement in this metric”, the actual outcomes naturally vary a lot depending on what is being twinned, and how good the data are. However, there are some proven and consistently seen benefits:
- Reduced unplanned downtime. This is linked to predictive maintenance; studies by industrial IoT vendors and research groups typically report reductions in the range of ~10–30%, depending on baseline maturity and asset criticality.
- Better decision making under uncertainty: often, it’s not the lack of real-time insights as such that limits operations but rather contextualized understanding of how systems behave. Digital twins close this gap by modeling, so different scenarios are evaluated faster – meaning planning is more accurate, too.
- Improved coordination. A common complaint across industries is how production, maintenance, and planning essentially live in “parallel universes”. Since digital twinning integrates data, it helps reduce such discrepancies, with less operational friction going on.
- Controlled process optimization. Since at a certain level of twinning, you can simulate changes before committing to them in the real world, there is more room for optimization and less risk.
Talking of ROI from digital twin initiatives, this is calculated based on the operational complexity – not just scale, but the nature of the production system itself. There’s a difference between, say, a craft brewery with several machines – and something like an automated assembly plant. In the former case, ROI will be gained from predictive maintenance and avoiding isolated but costly disruptions.
In the latter, when there are complex dependencies, the value will be mostly generated by small improvements in coordination or process timing that get amplified system-wide: cross-line optimization, detecting bottlenecks between processes, and so on – a completely different calculation.
Can SMEs actually use digital twins?
The notion of digital twinning is often associated with the “big fish” – large operations, big enterprises. This is largely because of marketing revolving around the most complex and spectacular, “NASA-level” use cases, though. In reality, SMEs can and do use digital twinning, albeit rarely as system-wide implementations.
Which makes sense – smaller, targeted applications that don’t attempt to model everything and rather focus on specific operational problems are easier to guarantee results. These are predictive maintenance solutions, simulations for specific workflows or bottlenecks, and so on. Such systems actually pave the way for fuller adoption later on, if equipment complexity increases, production becomes more variable, or scaling simply brings a more pronounced cumulative cost of inefficiencies.
In other words, for SMEs, digital twins are not an “all or nothing” question – there are plenty of contexts where implementing a less extravagant but conceptually similar solution is exactly what helps the company grow.
How to tell if your workflows are ready
We’ve seen that implementing a digital twin presupposes a certain level of readiness – that is, the data culture and the manufacturing processes can support the technology (and be supported by it) in a meaningful way.
In many environments, the key limitation is not the absence of data, but rather the lack of a consistent way of interpreting it across systems and teams. Which means the organization has to outgrow the manual information collection phase first.
Similarly, system connectivity is important – because digital twinning is about forming a coherent view of a certain operation, it needs to get rid of silos first.
Finally, readiness is also reflected in how decisions are made. If operational decisions rely heavily on manual reconciliation or informal knowledge, it usually indicates that the environment is still in an earlier stage of digital maturity. The good news is that reaching this level of maturity is achievable through cultural and organizational methods, not necessarily through heavy investment.
Preparing for digital twinning
Preparing manufacturing operations for digital twin implementation is not so much about choosing any specific tool as about operational conditions. The most interesting part is that this work brings value even on its own.
Here is a brief checklist of where to look:
- Data foundation
identify the key data sources across production and maintenancemake sure the machine and process data records are standardizedminimize manual data collection (where possible)ensure basic consistency (timestamps, identifiers, units)
- Try to connect your systems and find data silos
identify how data is supposed to flow between systemsprioritize integration points that have the highest operational impactmake sure there are no duplicates
- Find your high-impact use case: it could be some recurring failure, a production bottleneck, inefficiency in planning, or a visibility gap. This way, you not only increase the immediate impact, but also get to know what data is needed and what level of modeling to settle on.
- Teams and operational visibility:
establish shared metrics between production, maintenance, and planningclarify what “system status” means across departments
- Starting smartly: instead of trying to model the entire system, start with a single machine group or production line to validate assumptions.
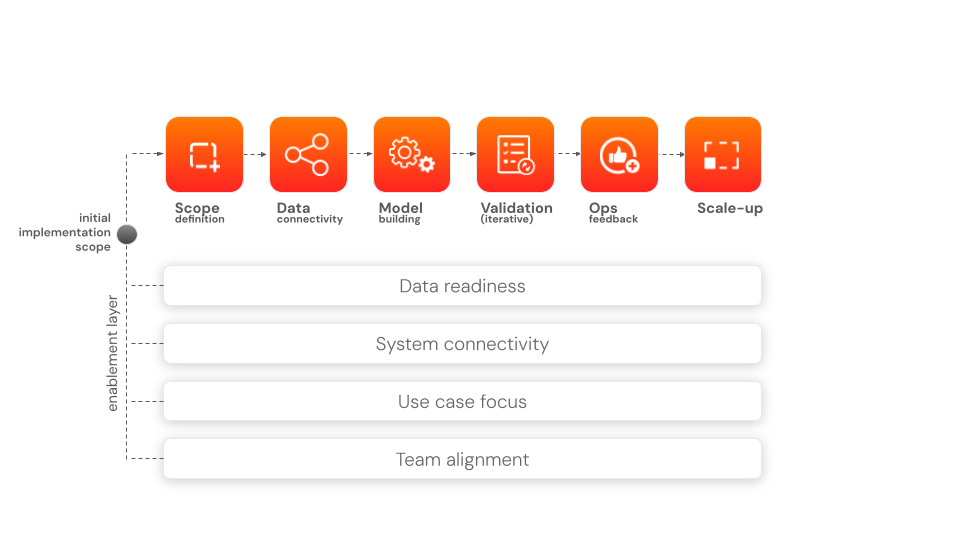
How digital twin implementation actually works
Digital twin implementation is often an incremental process – organizations prefer starting with a limited scope and gradually expand as data quality improves. This is what this looks like in practice:
#1 Defining the initial model scope
Everything starts by selecting a clearly bounded part of the production system. From an engineering perspective, this involves defining the “asset model” (what exactly is being represented), deciding which parameters are relevant (cycle time, load, temperature, etc.) – and establishing system boundaries (i.e. what you do and don’t include in the model). This helps prevent overscoping.
#2 Connecting physical systems to data pipelines
This is the connectivity stage: integrating sensor outputs, PLC, IoT streams and setting up data ingestion pipelines (e.g. via MQTT, OPC UA, or REST-based interfaces). This is also where cloud or edge infrastructure may be introduced depending on latency and processing requirements.
#3 Building the digital representation layer
The core phase – this is where the virtual model is created. Depending on the complexity, this may involve:
- rule-based models that define expected operational behavior
- statistical models that establish normal performance ranges
- machine learning components for anomaly detection or prediction
In more advanced setups, frameworks such as Python-based ML stacks (e.g. PyTorch or scikit-learn) are used to build predictive components, while simulation environments may be introduced for scenario testing.
#4 Validating against real-world behavior
This is where the model is tested against real operational data to see whether it reflects actual system behavior. The team identifies potential model drift and adjusts parameters or rules. In practice, this is often an iterative loop rather than a single check.
#5 Creating feedback loops for operational use
Once the model is stable enough, it begins to support operational decisions: dashboards showing system state, alerts, or simulation tools.
#6 Expanding scope over time
At some point, the now-mature system can be extended to additional machines or production lines, or cross-system integration can be introduced (like linking production with maintenance planning).
In most cases, value appears early, long before the system becomes “fully complete” – as long as the initial scope is well chosen and the data foundation is reliable.
What affects the cost of a digital twin?
The lasting misconception that digital twinning is a “monumental project” has a consequence – many still assume it’s about a large fixed investment. In practice, though, the cost of implementing a digital twin in manufacturing settings varies depending on several factors.
Most importantly, it’s the scope and level of detail. Modeling a single machine or process is a relatively contained effort, while a full production line will involve more complexity and higher integration. Data readiness and quality also play a role – additional data jobs, like cleaning and aligning datasets or filling gaps in sensor coverage add to the cost.
Modeling approaches also rank differently in complexity: rule-based monitoring is easier, making the implementation cheaper, while predictive models and simulations are on the other end of the spectrum.
In general, starting with a limited scope and then expanding where it’s needed is not just about avoiding large upfront investments, but also lowers the overall cost over time, because the evolution is more sensible and purpose-driven.
Conclusions: making Industry 4.0 practicable
Digital twins are often presented as a defining element of Industry 4.0. In practice, their value depends less on the concept itself and more on how realistically it is applied.
For some manufacturers, a full-scale digital twin may be unnecessary or premature. For others, it can become a meaningful step toward better operational visibility and control.
What remains consistent across different contexts is that successful implementations do not start with technology alone. They begin with three factors:
- clearly defined operational challenges
- a reliable data foundation
- and a willingness to approach implementation incrementally
In this sense, digital twins are not a one-time upgrade, but part of a broader shift toward making manufacturing systems more observable and adaptable.
If you’re considering how digital twin approaches could fit into your operations, starting with a clearly defined use case and a realistic assessment of your current systems is usually the most effective first step.





